(https://www.inflearn.com/course/%ED%81%AC%EB%A1%A4%EB%A7%81#description
를 참고하여 정리하는 영상입니다.)
노드 크롤링을 통해 csv, xlsx 파싱을 진행해 보려 한다.

npm i csv-parseCSV 파일 파싱하기
csvParinsg.js
const parse = require("csv-parse/lib/sync");
const fs = require("fs");
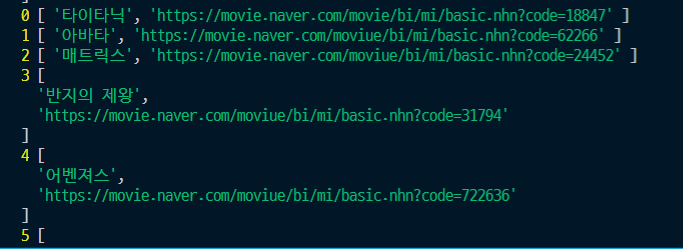
const csv = fs.readFileSync("./csv/data.csv");
console.log(csv.toString());
//parse 메서드 -> 2차원배열화
const records = parse(csv.toString());
console.log(records);
엑셀 파일 파싱하기

해당 엑셀파일의 데이터들을 파싱해 오려한다.
npm i xlsxconst xlsx = require("xlsx");
const workbook = xlsx.readFile("./xlsx/data.xlsx");
// 배열의 키값을 가져올때 사용하는 Object.keys
//영화목록시트가 담긴다
console.log(Object.keys(workbook.Sheets));
const ws = workbook.Sheets.영화목록;
console.log(ws);

엑셀의 records 가져오기
xlsxParsing.js
const xlsx = require("xlsx");
const workbook = xlsx.readFile("./xlsx/data.xlsx");
// 배열의 키값을 가져올때 사용하는 Object.keys
//영화목록시트가 담긴다
// console.log(Object.keys(workbook.Sheets));
const ws = workbook.Sheets.영화목록;
// console.log(ws);
//row들 가져오기
// sheet_to_json는 엑셀의 복잡한 데이터를 자바스크립트 객체로 변환해준다.
const records = xlsx.utils.sheet_to_json(ws);
console.log(records);

const xlsx = require("xlsx");
const workbook = xlsx.readFile("./xlsx/data.xlsx");
// 배열의 키값을 가져올때 사용하는 Object.keys
//영화목록시트가 담긴다
// console.log(Object.keys(workbook.Sheets));
const ws = workbook.Sheets.영화목록;
// console.log(ws);
//row들 가져오기
// sheet_to_json는 엑셀의 복잡한 데이터를 자바스크립트 객체로 변환해준다.
const records = xlsx.utils.sheet_to_json(ws);
// console.log(records);
records.forEach((r, i) => {
console.log(r.제목, r.링크);
});
// console.log(records.entries().next());
//비구조화 할당을 통해 첫번째 인자인 숫자부분에 i
// 그다음 객체 구조에 r을 할당해서 출력
//배열.entries를 쓰면 내부 배열이 [인덱스, 값] 모양 이터레이터로 변경된다
for(const [i, r] of records.entries()){
console.log(i, r);
console.log(r.제목);
}
records를 forEach를 통해 출력하거나
배열의 비구조화 할당 및 records.entrise()로 이터레이터로 변경해서 출력할 수 있다.

A, B 형태로 가져오기
const xlsx = require("xlsx");
const workbook = xlsx.readFile("./xlsx/data.xlsx");
// 배열의 키값을 가져올때 사용하는 Object.keys
//영화목록시트가 담긴다
// console.log(Object.keys(workbook.Sheets));
const ws = workbook.Sheets.영화목록;
// console.log(ws);
//row들 가져오기
// sheet_to_json는 엑셀의 복잡한 데이터를 자바스크립트 객체로 변환해준다.
const records = xlsx.utils.sheet_to_json(ws, {header :'A'});
console.log(records);

이렇게 console을 실행해주면
{A;"제목", B:'링크"} 가 나오게된다.
이를 해결하기위해 records.shit()로 해결하거나
split으로 A1부분을 A2로 바꾸는법도 가능하다
const xlsx = require("xlsx");
const workbook = xlsx.readFile("./xlsx/data.xlsx");
// 배열의 키값을 가져올때 사용하는 Object.keys
//영화목록시트가 담긴다
// console.log(Object.keys(workbook.Sheets));
const ws = workbook.Sheets.영화목록;
// console.log(ws);
//row들 가져오기
// sheet_to_json는 엑셀의 복잡한 데이터를 자바스크립트 객체로 변환해준다.
// header를 사용해줬을때 첫항 빼주기
// records.shift(); //첫번재 배열 A : '제목', B:'링크를 빼준다'
// A1 ~ B11 까지
console.log(ws['!ref']);
// A1 ~ B11 까지 -> A2: B11 까지로 바꿔주기
ws['!ref'] = ws['!ref'].split(":").map((v, i) => {
if(i === 0){
return "A2";
}
return v;
}).join(":");
// 이렇게 즉시 해도 가능하다
// ws['!ref'] = 'A2:B11';
const records = xlsx.utils.sheet_to_json(ws, {header :'A'});
console.log(records);

SheetNames를 활용하면 시트별로 이름도 가져올 수 있다.


본 글은 아래 인프런 강의를 듣고 작성된 내용입니다
https://www.inflearn.com/course/%ED%81%AC%EB%A1%A4%EB%A7%81
Node.js로 웹 크롤링하기 - 인프런 | 강의
네이버, 아마존, 트위터, 유튜브, 페이스북, 인스타그램, unsplash.com 등의 사이트를 크롤링하며 실전에 적용해봅니다., Node.js로 웹 크롤링하기 Node.js와 Puppeteer를 활용해 웹 사이트를 크롤링하여 원
www.inflearn.com
'Node.js > node crawling' 카테고리의 다른 글
| 노드 크롤링 - puppeteer의 다양한 기능들 (0) | 2020.08.15 |
|---|---|
| 노드 크롤링 - csv에 있는 주소를 통해 puppeteer 크롤링, csv파일 작성하기 (0) | 2020.08.15 |
| 노드 크롤링 - puppeteer 사용해보기 (0) | 2020.08.15 |
| 노드 크롤링 - 네이버 영화 크롤링하기, 엑셀에 작성하기 (0) | 2020.08.15 |
| puppeteer을 활용해서 스크린샷 찍기, 크롤링하기, pdf 생성하기 (0) | 2020.05.16 |



