기존에 회사에 운영되던 호출 파트중에 170만건의 데이터를 조회하는 조회시 2~4초 정도 걸리던 쿼리가 존재하였다.

코드를 활용해 최대한 최적화에 도전 (총 가져오는 갯수를 줄여본다거나, 날짜의 제한을 두고 조회한다거나 ) 여러가지 도전을 해봤지만 드라마틱한 속도의 개선은 일어나지 않았다.
DB INDEX
마지막으로 도전해본건 DB 인덱스 작업이였다. (공식 홈페이지)
https://www.postgresql.org/docs/current/indexes-intro.html
11.1. Introduction
11.1. Introduction # Suppose we have a table similar to this: CREATE TABLE test1 ( id integer, content varchar ); and …
www.postgresql.org
인덱스란?
장점
- 검색 성능 향상
- 정렬및 그룹화 성능 개선
- 대용량 데이터처리
기존에 DB에서 where 절로 검색할 경우 테이블의 첫번째 행부터 마지막 행까지 순차적으로 읽는 풀 테이블 스캔이 일어나게 되는데 인덱스를 생성하게 되면
인덱스를 추가하게되면 특정 컬럼의 값을 정렬된 구조(B-tree, Gin .. 등등) 로 저장하고 그값을 가리키는 방식을 제공한다.
따라서 인덱스를 통해 데이터의 위치를 찾고 바로 이동하기때문에 속도가 비약적으로 빨라진다.
단점
- 추가적인 저장 공간 필요
- 쓰기 성능 저하
- 중복이 많은 컬럼에 비효율적
인덱스는 테이블의 데이터를 추가적으로 저장하는 구조이기 때문에 인덱스가 많아질수록 저장공간이 증가한다.
인덱스는 삽입/수정시 인덱스가 있으면 인덱스도 같이 갱신하기 때문에 쓰기 성능 저하가 일어날수있다.
INSERT 연산시 새 데이터에 대한 인덱스 추가,
DELETE 연산시 삭제하는 데이터의 인덱스를 사용하지 않는 처리,
UPDATE 연산시 기존 인덱스를 사용하지 않고 갱신된 데이터에 대한 추가 처리
주의사항
인덱스는 메모리를 차지하며 무분별한 인덱스생성은 성능 저하 이슈가 발생할수 있기에 주로 해당 내용을 위주로 생성해야한다.
- 인덱스는 WHERE 절에서 자주 사용되는 컬럼
- JOIN에 자주 사용되는 컬럼
- 정렬과 그룹화에 사용되는 컬럼
- 중복이 적은 컬럼
적용하기
자주 사용될 부분에 대해 INDEX들을 생성해주었다.

인덱스를 생성한 후 기존 EXPLAIN 쿼리를 실행시켜주었다.
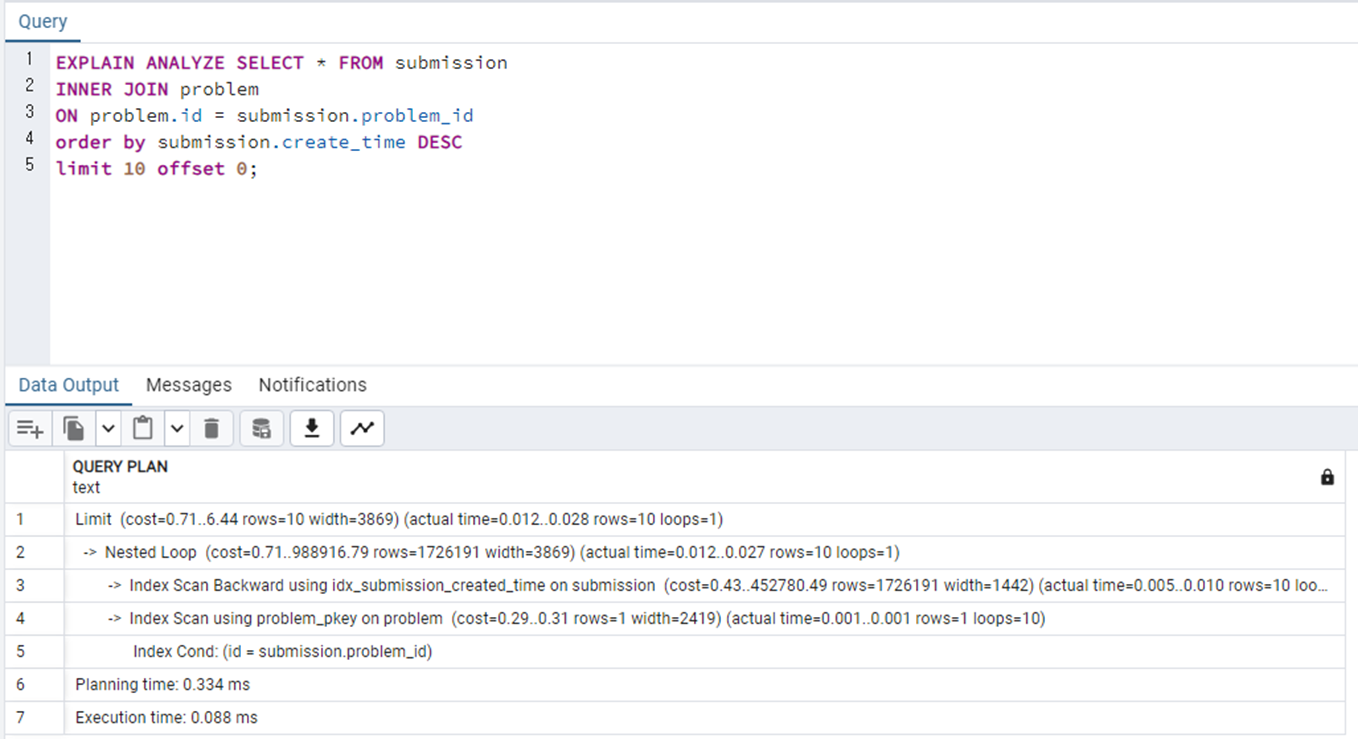
이렇게 INDEX를 통해 성능 최적화를 진행하였다.
LIKE 검색 성능 개선하기
이제 기본 쿼리는 굉장히 빨라졌지만 여기에서 %data% 검색시 여전히 full table sacn이 일어난걸 확인했다.
data% 형식은 기존 검색 처럼 INDEX를 활용한 검색이 진행되었지만 %data%는 data가 포함된 모든 경우를 찾아야해서
INDEX가 사용되지 않았다.
%data% 형식의 LIKE 검색은 기존 B-tree 인덱스 대신 Trigram Index를 채택하였다.
따라서 GIN INDEX로 trigram index를 생성해주었다.
GIN 인덱스 추가하기

해당 인덱스 추가후 적용해보면

해당 index를 사용해 적용된것을 확인할 수 있다.
'프로젝트 > 버그, 성능개선' 카테고리의 다른 글
| guincorn 메모리 누수 현상 해결하기 ( gunicorn memory leak ) (0) | 2024.09.25 |
|---|---|
| pinpoint django agent 적용하기 (0) | 2024.02.12 |
| spring boot pinpoint agent 설치하기 (3) | 2024.02.11 |
| APM 도구 pinpoint 설치하기 (0) | 2024.02.10 |
| 주요 APM 도구 분석하기 (0) | 2024.02.03 |



